
はじめに
はじめまして。ソリューションC&I本部の豊田です。
普段はIBMi(AS/400)を中心とした開発案件を担当しております。
今回、お客様の案件でAmazonのQuickSight(BIサービス)に触れる機会がありましたので、実装手順などを中心にお伝えしたいと思います。
QuickSightとは
QuickSight は主に以下の特徴があります。
-
インフラ管理が不要
AWSのフルマネージドサービスであるためソフトのインストール、アップグレードのソフトウェアメンテナンスが不要。
-
高いコスト効果
従量課金、Author / Readerの2種類のユーザータイプの料金設定。
-
アプリケーションへの容易な組み込み
QuickSightで作成したダッシュボードをポータルやWebアプリに埋め込み可能。
-
機能学習のインサイト機能
機能学習ベースの異常検知、予測やデータ内容をもとに分析結果を自動で文書化可能。
詳細はこちらをご参照ください。
やりたいこと
今回はAmazon Redshiftに格納されたデータをQuickSightで可視化してみようと思います。
以下のようなイメージです。
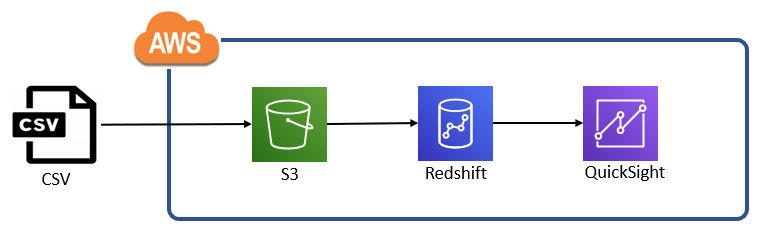
流れとしては
・元となるCSVデータをS3のバケットに格納
・S3のCSVデータをRedshiftのテーブルロード
・RedshiftにロードされたデータをQuickSightで可視化
です。
事前準備
1.AWSアカウントの作成
AWSのアカウントを作成します。
詳細は割愛します。
2.IAM Roleの作成
S3にアップロードしたCSVデータをRedshiftにロードする際に使用するIAM Roleを新規作成します。
以下のようにS3とRedshiftへの権限を付与します。

3.QuickSightからRedshiftクラスターへのアクセスを有効化
QuickSightからRedshiftのデータを参照できるようにアクセス権限を有効化させます。
VPC マネージメントコンソールで「セキュリティペイン」を選択しセキュリティグループを作成します。
今回は例として「Amazon-QuickSight-access」というセキュリティグループを作成してます。
・VPC-ID・・・RedshiftのVPC-ID
・Port ・・・RedshiftのPort番号

続いて作成した「セキュリティグループ」をRedshiftのセキュリティグループに追加します。
Redshiftマネジメントコンソールの「クラスター」ページに戻り、アクセスを有効にするセキュリティグループを追加します。
以下は設定後の画面です。

4.Redshiftに格納するサンプルデータの用意(CSV形式)
以下のようなサンプルデータを用意しました。
注意点としてRedshiftで扱える文字コードはUTF-8のみです。
S-JISなどの文字コードの場合はエディタ等でUTF-8に変換しておきましょう。

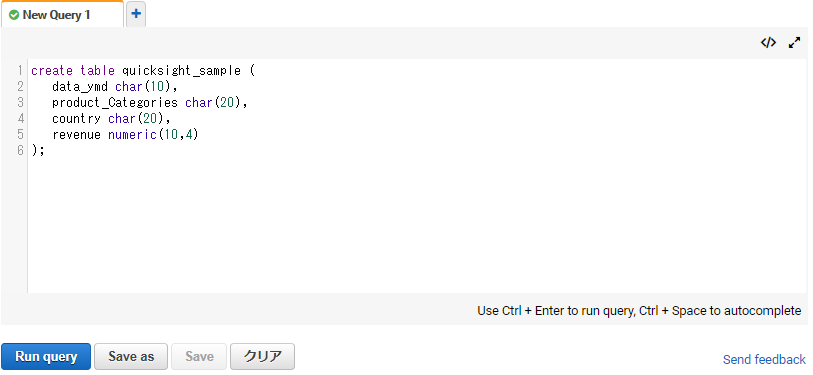
5.Redshiftにテーブルを作成
Redshiftにテーブルを作成します。
今回はRedshiftのQuery editorで作成してます。
以上で準備完了です。
やってみる
それでは以下の一連の流れをやってみます。
・CSVデータをS3にアップロード
・S3のCSVデータをRedshiftにロード
・QuickSightからRedshiftのデータを可視化
1.AWS S3にCSVデータをアップロード
S3に任意のバケットを作成して、準備行程で作成したCSVデータをアップロードします。

2.S3からRedshiftにデータをロード
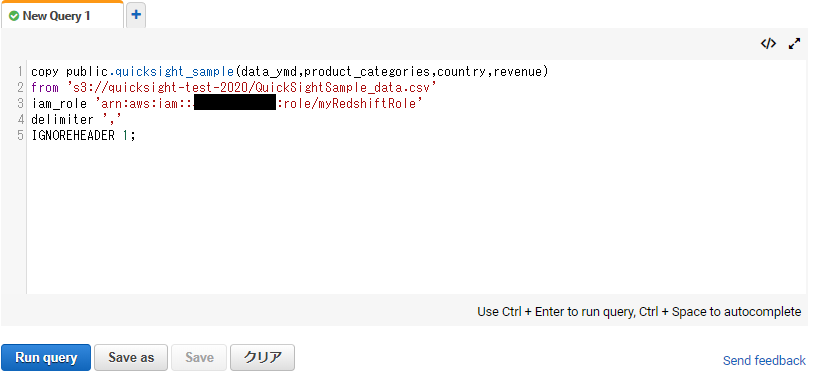
S3にアップロードしたCSVデータをRedshiftにロードします。
以下のようにCOPYコマンドを使用してデータを格納してます。
・FROM句にS3のパスを記述
・IAM ROLEには事前準備工程で作成したIAM ROLEのIDを記述
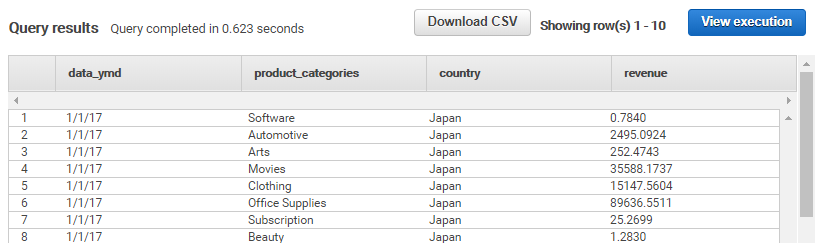
コマンド実行後、Redshiftのテーブルに正しくデータが格納されていることを確認します。
3.QuickSightで参照するRedshiftのテーブルを選択
AWSコンソール画面のサービスメニューから「QuickSight」を選択します。

QuickSight画面の左上部にある「新しいデータセット」を選択します。
QuickSightで扱うことのできる様々なデータソースが表示されます。
一覧画面から「Redshift 自動検出」を選択します。

続いてRedshiftのデータソース情報を入力します。

続いてRedshift内にある可視化可能なテーブルが表示されます。
サンプルとして作成した「quicksight_sample」テーブルを選択します。

続いて参照方法を選択します。
SPICE(インメモリエンジン)にデータをインポートしたうえでアクセスするか、直接データソースへアクセスするかいずれかを選択します。
SPICEに格納するとクエリの処理速度の高速化が図れますが格納できるデータ要領に制限があるので注意が必要です。
今回は「データクエリを直接実行」を選択してます。
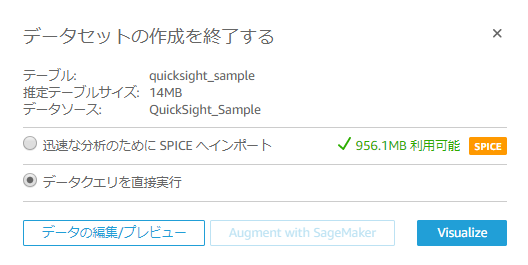
4.QuickSightでデータを可視化
QuickSightの画面が表示されます。

可視化したいグラフや抽出条件を任意で指定します。
例として画面中央にある日のカテゴリ別の収益を円グラフで表示し、右側には内訳となるデータをテーブル化したものを表示してみました。

無事、RedshfitのデータをQuickSightで可視化することができました。
終わりに
今回はRedshiftへのデータの格納やQuickSightの可視化の手順に着目してお伝えしました。
QuickSightの詳しい使用例など、また機会がありましたら
お伝えしたいと思います。
最後までお付き合いいただきありがとうございました。
今後も新しい技術・サービスを日々探求していきたいと思います。